Data import
From WebMetabase processed experiments
The experimental data that has been processed in WebMetabase that have been approved by the user is later linked to the Compound Library. The parent structure is automatically loaded into the Compound Library, if the compound already exists the system will add to the existing compound record in the Compound Library database a link to the new experiment and it will automatically import the retention time, the Area for any signal reported in the experiment, the CCS (Collision Cross Section) (Cross Collision Section value, the Mass Spectra, and the interpretation of the Mass Spectra.
When there are more than one WebMetabase experiment linked to a compound record the user can access the functionalities that compare the result to multiple experiments to obtain a single metabolite nomenclature for all the metabolites in the database and therefore have a single report for a collection of the experiments.
Along with the structure of the parent compound, the system also adds a record for the metabolites that have a single molecular structure associated. The metabolites inside a WebMetabase experiment that have a Markush representation, more than one structure is compatible with the reported Mass spectra data are not imported. The information that is reported in the Compound Library for the metabolite with single structure is the same as the one found for the parent.
If the user Edit again the experiment in WebMetabase the compound records are kept into the Compound Library but the link to the experiment is removed.
From WebQuant processed experiments
The experimental data that has been processed in WebQuant that have been approved by the user is later linked to the Compound Library. The compound structure is automatically loaded into the Compound Library, if the compound already exists the system will add to the existing compound record in the Compound Library database a link to the new experiment and it will automatically import the retention time, the Area for any signal reported in the experiment, the CCS (Collision Cross Section) (Cross Collision Section value, the Mass Spectra, the interpretation of the Mass Spectra and also the end points that were defined in the protocol definition of the WebQuant experiment.
If the user Edit again the experiment in WebQuant the compound records are kept into the Compound Library but the link to the experiment is removed
From WebChembase processed experiments
The experimental data that has been processed in WebChembase that have been approved by the user is later linked to the Compound Library. The reactant structures are automatically loaded into the Compound Library, if the compound already exists the system will add to the existing compound record in the Compound Library database a link to the new experiment and it will automatically import the retention time, the Area for any signal reported in the experiment, the CCS (Collision Cross Section) (Cross Collision Section value, the Mass Spectra, and the interpretation of the Mass Spectra.
When there are more than one WebChembase experiment linked to a compound record the user can access the functionalities that compare the result to multiple experiments to obtain a specific product nomenclature for all the products in the database and therefore have a single report for a collection of the experiments.
Along with the structure of the reactant compound, the system also adds a record for the products that have a single molecular structure associated. The products inside a WebChembase experiment that have a Markush representation, more than one structure is compatible with the reported Mass spectra data are not imported. The information that is reported in the Compound Library for the product with single structure is the same as the one found for the parent.
If the user Edit again the experiment in WebChembase the compound records are kept into the Compound Library but the link to the experiment is removed.
From SDF
This functionality is used to import a SDF file with one or more than one molecule into the compound library, also the tags that are associated to each of the compounds in the database can be imported. If the molecule is already existing in the database as identified by the InChiKey computed by the system it will not be imported, but the associated information reported as the tags could be imported if indicated by the user.
There are two panel in the sdf import function:
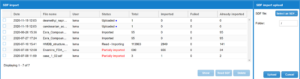
Compound Library: Import sdf
- Sdf Import upload panel: In this panel the user can select the sdf file to be imported. After the file has been selected the user can also select the folder where the compounds from the sdf will be imported to.
- Compound Library: Import Sdf – Sdf table: The SDF import table contains as rows, the different SDF files that have been imported into the system. The user can select a row that has not been imported and read the data into the system and click the Read SDF button to start the importing window.
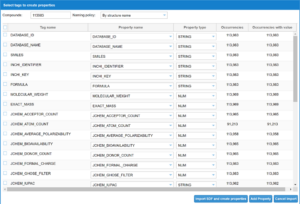
Compound Library: Import sdf – Importing window
On the top of the table there is the information about the number of compounds that are included in the sdf and the selection of the naming policy of the compounds once they will be imported.
The table contain the variables that could be imported from the sdf tags as rows. Each column represents:
- Tag name: This is the name of the variable as shown as a tag in the sdf file.
- Property name: This is the name of the property inside the Compound Library.
- Property type: This is the type (STRING, NUMBER or DATE) of the property.
- Occurrences: This indicates the number of compounds that has the property defined in the tag of the SDF.
- Occurrences with value: This indicated how many times the existing property has a value associated with the tag in the SDF.
From Comma separated files
The system can also import several properties for multiple compounds in a comma separated file. This work has multiple steps, and it is accessible from the Exp Data Import button at the Compound Library initial page. To illustrate the process a csv shown in the next window will be used in a database that already contains the compounds that the data have been imported. One condition to apply this action is that the compounds need to be already existing in the database.

Compound Library: Experimental data import. Csv example
After the user selects the Exp Data Import, the file can be selected from the file system. Once the file has been uploaded it will appear in the CSV (Comma Separated Values) import table. Each row in this table corresponds to an uploaded csv file.
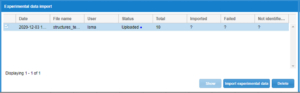
Compound Library: Experimental data import. CSV (Comma Separated Values) import table
Each column in the table corresponds to:
- Date: The date that the file was uploaded.
- File name: Name of the file uploaded.
- User: Name of the suer that uploaded the file.
- Status: Status of the importing process. There are 3 statuses:
- Uploaded: The file has been imported into the system.
- Imported: All the rows of the csv file have been imported into the system.
- Partially imported: Some of the rows in the csv file have been imported.
- Total: Total number of rows in the csv file.
- Imported: Number of rows successfully imported.
- Failed: Number of compounds that have failed to import.
- Not imported: Number of compounds that could not be imported.
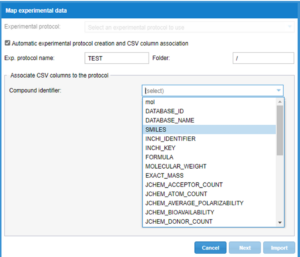
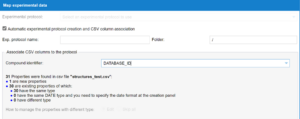
After the user selects to Import Experimental data the importing process will continue. The first step is to select an existing Experimental protocol to map the properties of the csv with the properties defined in an already existing protocol, or to select the “Automatic Experimental protocol creation and CSV association.”
From the list of Associate CSV columns to the protocol select which column in the CVS file will be used as the Compound identifier from the database. From the combo box select the name of the column in the csv file to be used as compound identifier. Also type the name of the Exp protocol name that will be used during the importing of the file.
Compound Library: Experimental data import.
When the process will be done a new window will show the results from the mapping process. It will show the number of properties found in the csv file (columns), the new of new properties as not already defined in the database as “new properties”, and the window also show the already existing properties in the database, and it compared the type of the property. If the guessed type of the property from the csv file it is different from the existing type in the database it will be reported in this window and the suer will need to change the name of the property, since there cannot be 2 properties in the database with the same name and different type.
Compound Library: Experimental data import.
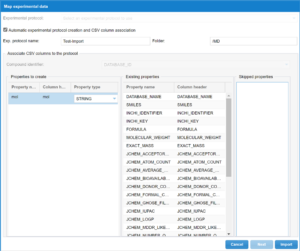
On the next step the system will show the properties that have been automatically mapped, the new properties that will be created, where the user can select the property type and the Skipped properties because they had the same name and different type.
Compound Library: Experimental data import.
After importing the file, it will show the status of the import in the table.

Compound Library: Experimental data import.